Key Takeaway
- Backpropagation passes error backward from the output layer
- Each weight’s desired change is proportional to: how wrong the output was × how active the sending neuron was × how many neurons send similar signals
- The final gradient is the average of these nudges over all training examples
This chapter answers:
How do we compute which weight/bias should change, and by how much?
Introduce
Backpropagation is the core algorithm that tells every parameter how it should move to reduce cost.
- Key intuition: start from output error, pass responsibility backward layer by layer.
Recap
- Network forward pass:
- Input image (784 pixels) goes through layers.
- Output layer gives activations (10 numbers for digits 0~9).
- Training target:
- Minimize cost
- θ = model parameters (weights, biases)
- D = dataset (training data)
- Find the best set of parameters θ so that the model’s error on the dataset DDD is as small as possible.
- Minimize cost
- Gradient descent update:
- Missing piece before this chapter:
- How to compute all partial derivatives efficiently.
What’s cost of the different?

- know the total cost of the network
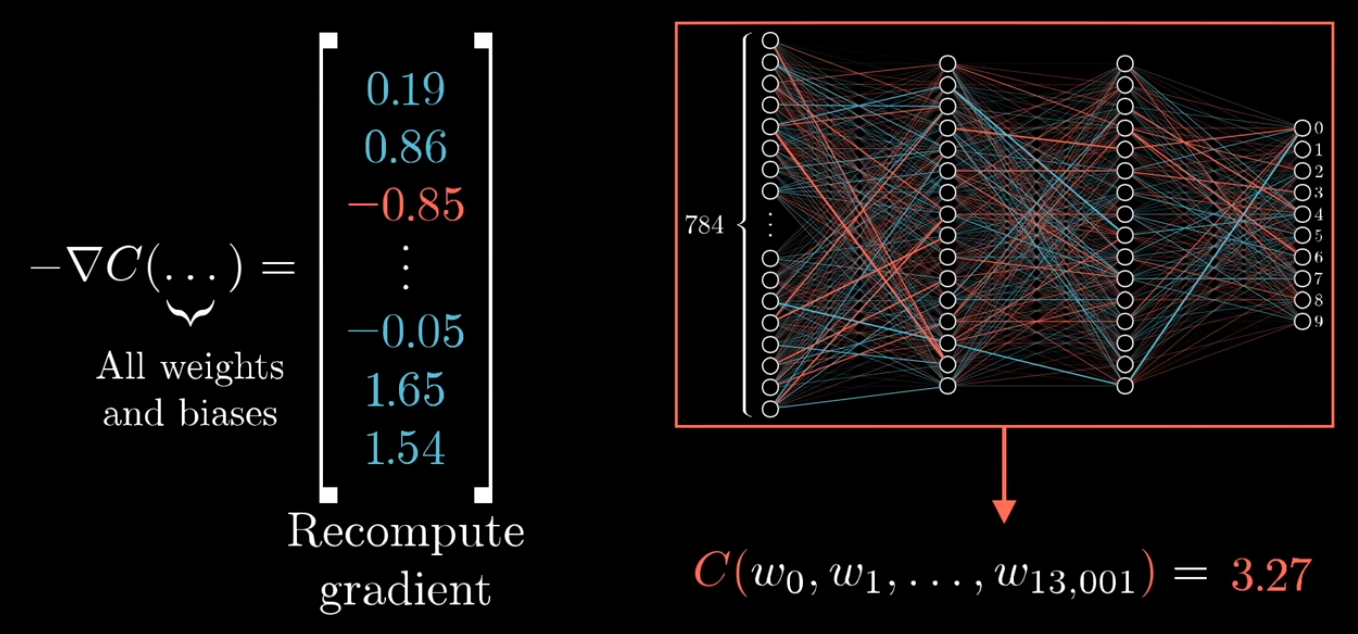
-
-
The gradient vector is built component by component. Each component is a partial derivative with respect to one parameter, computed while keeping all other parameters fixed.
-
See details: Cost vs Gradient in Neural Networks
Neural network contains many parameters (weights and biases). During training, these parameters are adjusted using gradients to minimize the cost function.
To lower the cost effectively, we need to know how each parameter affects the final output. However, computing the gradient for every parameter one by one would be far too inefficient.
That is why we use backpropagation. It is an efficient algorithm for computing the gradients of all parameters in the network.
Backpropagation
Backpropagation uses the chain rule to pass the final error backward through the network, so we can compute each layer’s gradients efficiently.
Process
Start from the final cost
↓
Determine how the output layer affects the cost
↓
Determine how the previous layer affects the output layer
↓
Determine how earlier layers affect the previous layer
↓
Propagate backward layer by layer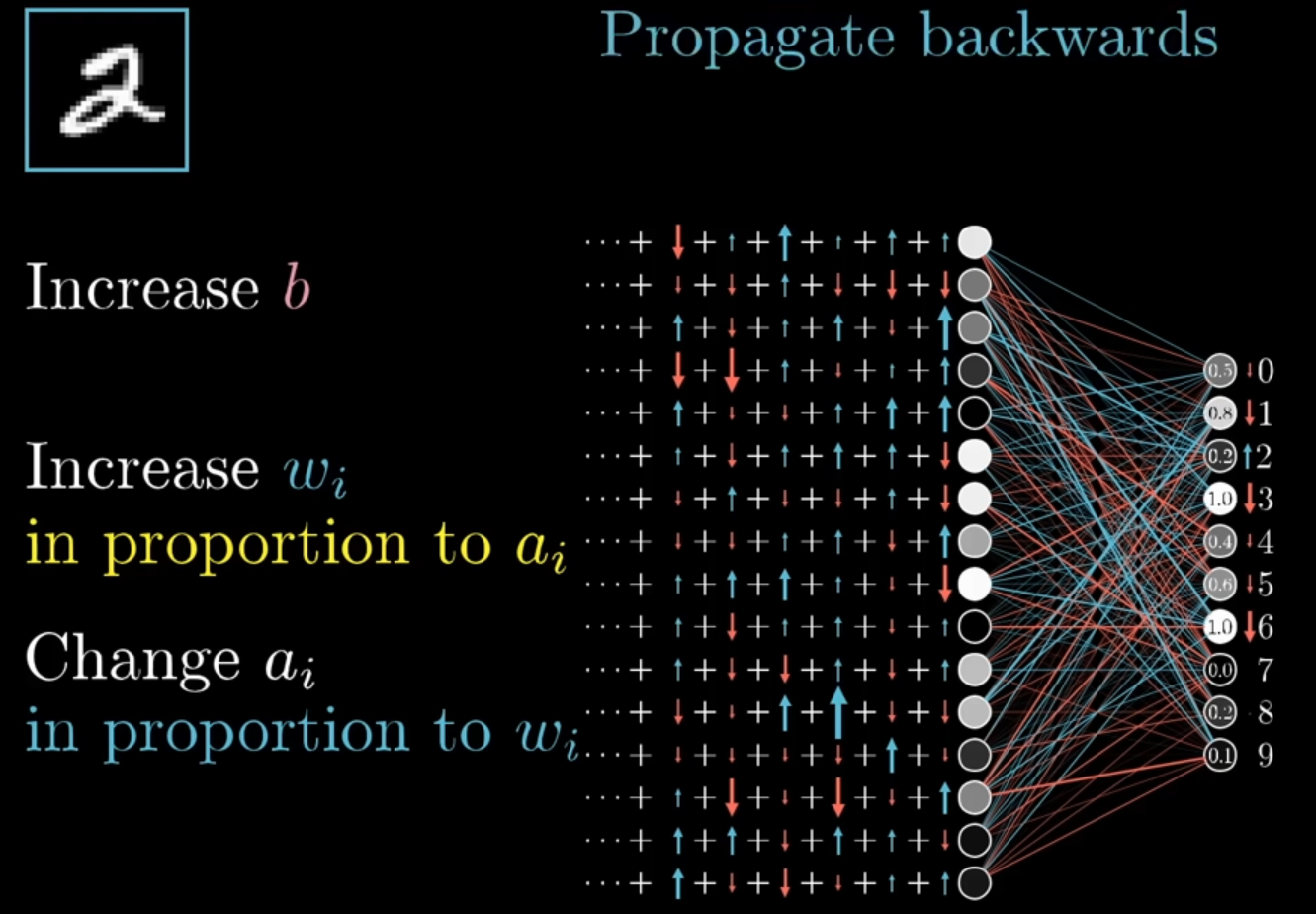
Also, if we trained the network using only images of the digit 2, the learned weights and biases would be heavily biased toward predicting 2.
In that case, the network might output something close to 2 for almost every input.
To learn meaningful weights and biases, the network must be trained on many different examples from different classes. During training, we randomly sample examples or mini-batches from the dataset to estimate the gradient and update the parameters. This is the basic idea behind stochastic gradient descent.
Stochastic Gradient Descent (SGD):
- Since using the entire training set for every parameter update is computationally expensive, we instead use small mini-batches of data
- (for example, 100 training examples) to approximate the gradient. This makes training much faster, although the path down the cost surface becomes noisier and less precise.
Formula
| Name | Formula | Meaning | Purpose |
|---|---|---|---|
| Output layer error | output error signal = cost sensitivity × activation slope | Compute the error signal for the output layer. | |
| Hidden layer error | backpropagated next-layer error × local activation slope | Compute the error signal for a hidden layer. | |
| Bias gradient | bias gradient = neuron error signal | The gradient of the bias equals the neuron’s error signal. | |
| Weight gradient | weight gradient = input activation × output neuron error | The gradient of a weight equals input activation times output error signal. |
- See Details: Symbol ∇ nabla
Backpropagation Formula Flow
output error → hidden error → bias gradient → weight gradient → update parameters
- First, compute the output error signal.
- Then, use it to compute the hidden layer error signal by passing the error backward through the weights.
- Once a layer’s error signal is known:
- its bias gradient is that error signal
- its weight gradient is previous activation × current error signal
- Finally, update the weights and biases.
Formula: Output layer error
- output: Error signal
- Purpose: to determine how much each neuron in the output layer contributes to the overall error.
- Meaning: the error at the output layer equals the cost sensitivity times the activation slope.
At the output layer:
- Cost sensitivity measures how much the cost cares about the output, while activation slope measures how easily the neuron output changes with respect to its input.
- cost sensitivity =
- activation slope =
- Symbol:
- : delta
- error / sensitivity of the output layer (the error signal for each neuron in layer )
- : nabla
- gradient of the cost function with respect to the output activations
- : sigma
- derivative of the activation function evaluated at
- : element-wise multiplication (Hadamard product)
- : weighted input of the output layer, computed as
- : cost (loss) function that measures how far the prediction is from the target
- : delta
Hadamard product
: element-wise multiplication (Hadamard product)
Example:
- Meaning: multiply corresponding elements position by position.
- e.g.
1. What is Cost Sensitivity?
Cost sensitivity means:
If
achanges a little, how much doescostchange?
how much the cost changes if the output activation changes a little.
-
Mathematically:
-
For neuron in the output layer:
-
Meaning: if the output changes slightly, how much will the cost change?
Example: Quadratic Cost
-
If the cost function is
- Make the partial derivative easier and cleaner by adding 1/2.
-
Then
-
So in this case: cost sensitivity = prediction − target
-
Example 1
- If:
- prediction
- target
- Then
- If:
-
Example 2
- If:
- prediction $a = 0.8
- target
- Then
- If:
Interpretation: If prediction and target differ a lot, the sensitivity will be large.
2. What is Activation Slope?
if
zchanges a little, how much doesachange?
- activation function = (sigma)
Activation slope means: the derivative of the activation function.
- If
- then
- represents how much the output activation changes if the input changes.
If the activation function is Sigmoid
-
Sigmoid:
-
Derivative:
-
Since , we often write
-
Example
- If a neuron’s output activation is
- Then
- So the activation slope = 0.16.
If the activation function is ReLU
-
ReLU:
-
Derivative:
-
So:
- if , activation slope = 1
- if , activation slope = 0
3. Combining the Two
For a single neuron at the output layer:
This means:
neuron error = cost sensitivity × activation slope
Example: Sigmoid + Quadratic Cost
- Assume:
- target
- output
- Step 1 — Cost Sensitivity
- Step 2 — Activation Slope
- Step 3 — Multiply
This value is the error signal for that output neuron.